How Does Fault Tolerance Provide Continuous Availability
Are you struggling to understand the differences between fault tolerance vs high availability vs redundancy? Does your organization need fault-tolerant servers?
Although easily confused, fault tolerance and high availability are not the same things. Without the high availability of a server connection, fault tolerance is a moot function.
Let's look at the differences between fault tolerance vs redundancy vs high availability in full.
What is Fault Tolerance (FT)?
Fault tolerance (FT) is a form of redundancy, enabling visitors to access the system in the event of the failure of one or more components.
When comparing fault tolerance vs high availability, fault tolerance enables visitors to still receive the requested site or application with limited functionality in the event of a failure of any component, whereas high availability is designed to keep all systems online using automatic failover mechanisms to transfer traffic and workloads to fully-functioning nodes automatically.
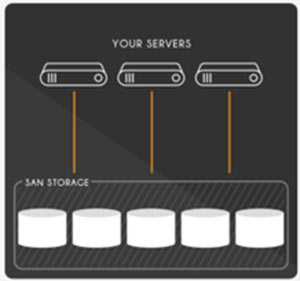
Fault tolerance is achieved through a storage area network (SAN). Using extremely fast, low latency gigabit ethernet connected directly to the servers, a SAN is an extremely scalable and fault-tolerant central network storage cluster for critical data. Users transfer data sequentially, or parallel, without affecting the performance of the host server.
What is Redundancy?
Redundancy is a necessary component to high availability. Redundancy can be best understood as two servers with duplicate or mirrored data. When comparing high availability vs redundancy, HA includes implementation of automatic failover in case of any type of failure, whereas redundancy speaks to the removal of points of hardware or software failure specifically. Or alternatively, when comparing fault tolerance vs redundancy, FT is all about ensuring minimal and core business operations stay online whereas redundancy is only concerned with duplication of hardware and software.
What is High Availability (HA)?
Highly available (HA) servers are designed to have maximum uptime by removing all single points of failure in order to keep mission-critical applications and websites online during catastrophic events, spikes in traffic, malicious attacks, or hardware failure. HA is implementing redundancy in infrastructure in order to stay online. You can have redundancy without high availability, but you cannot have high availability without redundancy.
VMware Private Cloud is fully redundant at the software and hardware levels using multiple nodes, a hardware switch, a load balancer, and VMware Center, vSphere, and the Distributed Resource Scheduler.
A High Availability Hardware Environment
All Internet traffic passes through servers housed somewhere and maintained by someone.
With this in mind, three things are universal:
- Not all servers are created equal.
- All servers have a finite lifespan.
- Sometimes servers just break.
Hardware failure is the most common contributor to low availability.
The soul-crushing inevitability of these universal truths is happily alleviated through redundancy.
Redundancy is key to server uptime by establishing a High Availability Hardware Environment. This is accomplished by assigning more than one server and a floating IP address with data replication to keep them in sync as a failover mechanism."
For configurations using KVM, another helpful function supporting redundancy and maintaining HA is a Distributed Replicated Block Device (DRBD®), which allows data to be mirrored between the servers and maintain synchronicity.
In addition, a clustered infrastructure of services called Heartbeat provides resource monitoring and messaging to facilitate failover and maintain high availability.
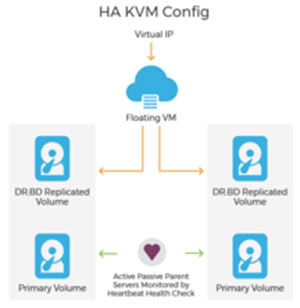
When a server fails, it triggers the second server to take over, ensuring traffic continues to flow with minimal interruption. Depending on the nature and cause of the failure, the visitor can be directed to the fault-tolerant failsafe.
Fault Tolerance Through Multiple Server Access
Think of computer storage as an elaborate transit system and data as tiny people trying to get somewhere efficiently without spilling their coffee.
This is done with Multipath I/O (MPIO), a fault-tolerance and performance-enhancement technique.
Connected through buses, controllers, switches, and bridge devices, more than one physical path between the central processing unit (CPU) in a computer system and its mass-storage devices is defined.
Like commuting during a cold winter, it's all about layering.
MPIO layers can leverage the redundant paths to provide performance-enhancing dynamic load balancing. Sites have hundreds (sometimes millions) of visitors, each making requests for text, images, videos, etc. as they navigate through the site."
Dynamic load balancing ensures quick access.
Staying with the transit analogy, load balancing is the person in the reflective vest standing in the intersection of the servers directing traffic.
If one server houses an ultra-popular data asset, it will get overworked and degrade disproportionately, so the data and requests need to be distributed across the web cluster.
The movement of data assets can be ultra-fast and confusing, creating complicated pathways. The MPIO algorithmic load balancing technique maximizes speed and capacity utilization.
If a server falters, the load balancer redirects traffic to the remaining online servers. If a new server is added to the cluster, the load balancer automatically directs requests to it.
The complicated redundancy and failsafe protection support fault tolerance.
In simple terms, the redundancy through fault tolerance ensures that visitors at least get a portion of the web experience and enough information to make a fair judgment, and retain a positive brand perception.
Web Hosting Reliability
Without a high availability environment, websites just don't load, and fault tolerance won't save it. Sometimes things break down completely and a 5xx error message begging the visitor to return later is the only answer.
However, non-catastrophic malware attacks, data corruption, or single server breakdowns are mitigated by Liquid Web's infrastructure, and these protections can be accessed by choosing the correct web hosting configuration.
To further enhance fault tolerance and reliability, the environmental processing systems include Liebert Precision 22-ton up flow air conditioning units that contain independent compressors and cooling loops.
Speaking with a technical professional to work through solutions after a server failure can be costly but the proper server protection package can reduce hacking-related support interactions by over 200%.
Reliability in cloud services maintains revenue and reputation.
Professionals who understand how people discover products, services, and information, and how their experience in the discovery process affects brand trust and decision-making, also understand that fault tolerance and high availability are crucial to that perception and decision-making process.
Companies that spend valuable time and money to create the face of their business should have all of the mechanisms at hand to ensure a consistent and available customer experience.
Ready to Achieve High Availability? Get the Ultimate High Availability Checklist For Your Website.

Source: https://www.liquidweb.com/blog/fault-tolerance/
0 Response to "How Does Fault Tolerance Provide Continuous Availability"
Post a Comment